背景
现有机器学习系统无法直接处理文本数据,一般需要进行向量化,这个过程叫做Word Embedding(词嵌入)。
过去多年最常用的向量化方式是基于统计的离散方法表示,如独热编码(One-hot Representation)、词频-逆文本(TF-IDF)、词袋模型(Bag of Words)、N-gram等。
2013年,Word2Vec横空出世(相关论文见 #参考文档),自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法模型出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的Word2Vec、doc2vec算法,基于物品序列的item2vec算法,基于图模型的图嵌入技术相继诞生。Distributed Representation 逐渐流行起来。
小结一下主流的文本向量化方法。
离散表示方法:
- 独热编码(One-hot Representation)
- 词频-逆文本(TF-IDF)
- 词袋模型(Bag of Words)
- N-gram
基于聚类的分布式表示
基于神经网络的分布式表示方法:
- Word2Vec
- Glove(Global Vectors)
- FastText(facebook)
在自然语言处理领域,单词的密集向量表示称为词嵌入(word embedding)或者单词的分布式表示(distributed representation)。过去,将基于计数的方法获得的单词向量称为distributional representation,将使用神经网络的基于推理的方法获得的单词向量称为distributed representation。不过,中文里二者都译为“分布式表示”。
Word Embedding
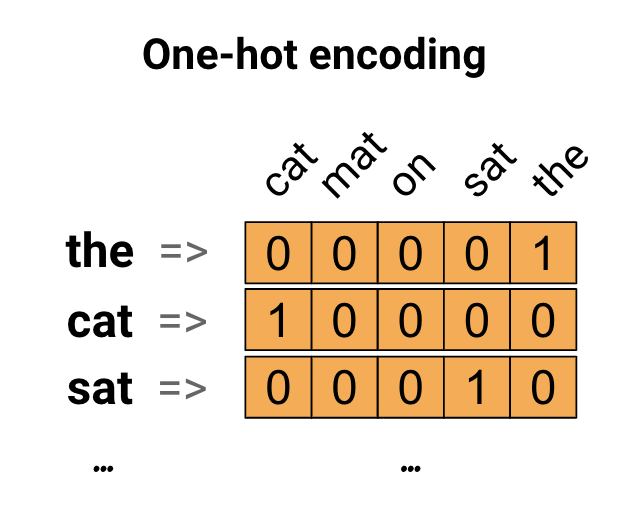
当单词数目增加时,传统的One-Hot编码的向量将是一个巨大的稀疏矩阵。Embedding层则是将离散实例连续化的映射,通过Embedding算法可以将离散词向量(如One-Hot编码,稀疏矩阵)映射成一个连续稠密向量。在这里引入Embedding层的目的是为了降维(当然Embedding层可以用来升维增加特征细节),常见的降维算法包括但不限于:
- 经典降维方法:如主成分分析(PCA)
- 经典矩阵分解方法:如奇异值分解(SVD)
- 基于神经网络的方法:如静态向量 embedding(如 word2vec、GloVe 和 FastText)和动态向量 embedding(如 ELMo、GPT 和 BERT)
- 基于Graph的embedding方法:图数据的 embedding 方法,包括浅层图模型(如 DeepWalk、Node2vec 和 Metapath2vec)和深度图模型(如基于谱的 GCN 和基于空间的 GraphSAGE)等
什么样的数据什么任务可以使用embedding层?

分布式表示的方法
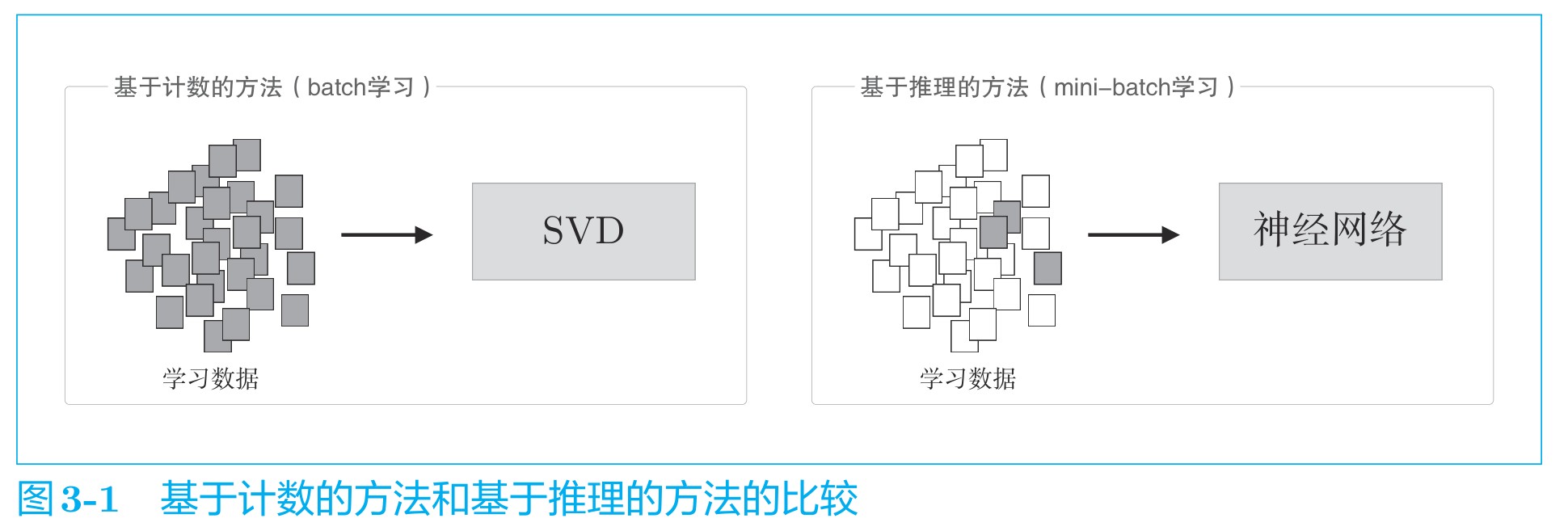
基于推理的Word2Vec
基于推理的方法是使用神经网络,通常在mini-batch数据上进行学习,每次只看一部分学习数据,并反复更新权重。Word2Vec有两种训练模型: CBOW(Continuous Bag-of-Word)和Skip-Gram。
CBOW模型
CBOW 模型是根据上下文预测目标词的神经网络(“目标词”是指中间的单词,它周围的单词是“上下文”)。
模型结构
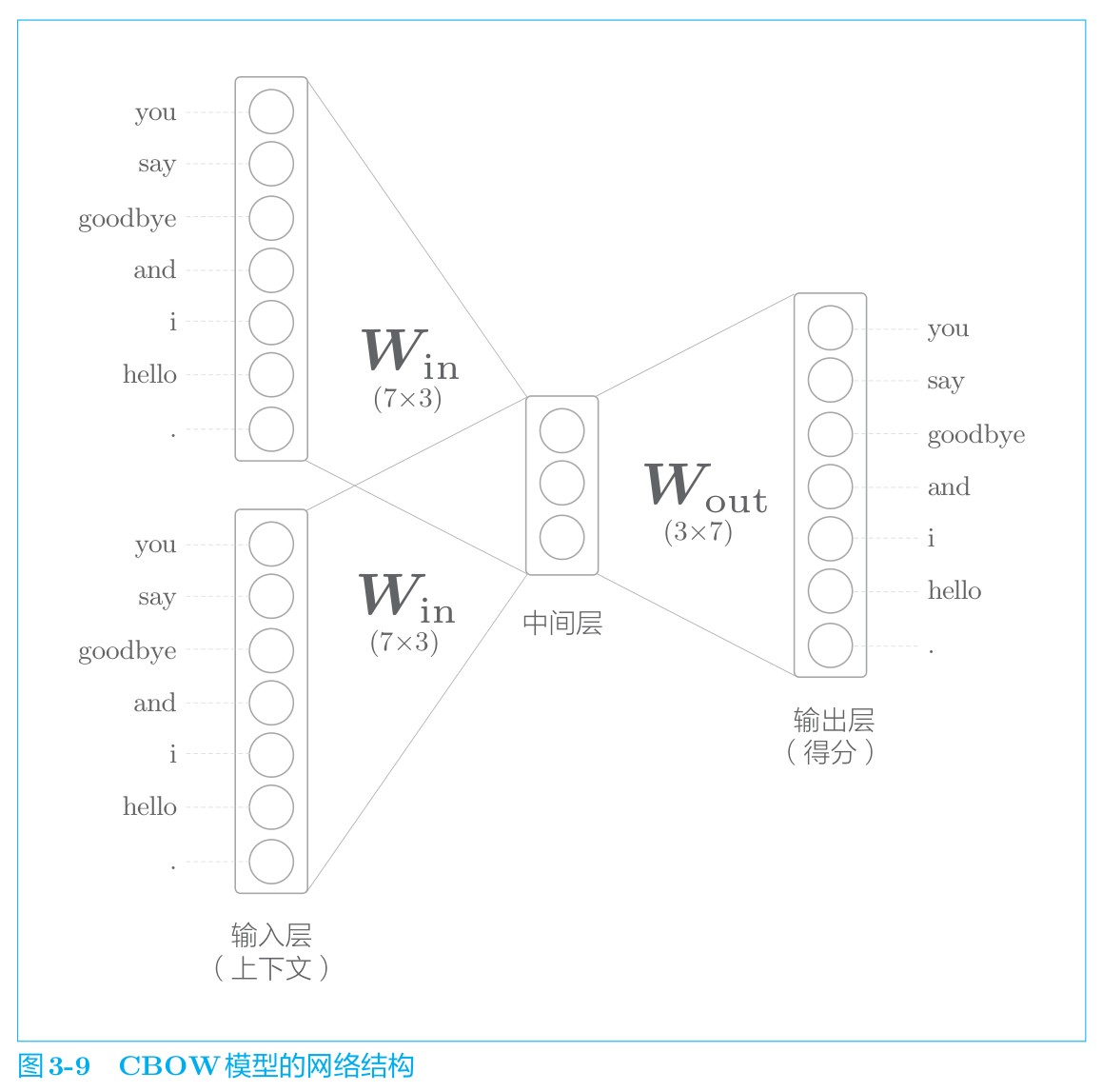
模型中间层的神经元是各个输入层经全连接层变换后得到的值的“平均”。就上面的例子而言,经全连接层变换后,第 1 个输入层转化为 h1,第 2 个输入层转化为 h2,那么中间层的神经元是 1/2(h1 + h2)。最后是图 中的输出层,这个输出层有 7 个神经元。这里重要的是,这些神经元对应于各个单词。输出层的神经元是各个单词的得分,它的值越大,说明对应单词的出现概率就越高。得分是指在被解释为概率之前的值,对这些得分应用 Softmax 函数,就可以得到概率。

全连接层的权重 $ W_{in} $ 是一个 7 × 3 的矩阵,这个权重就是单词的分布式表示。权重$ W_{in} $的各行保存着各个单词的分布式表示。通过反复学习,不断更新各个单词的分布式表示,以正确地从上下文预测出应当出现的单词。令人惊讶的是,如此获得的向量很好地对单词含义进行了编码。这就是 Word2Vec 的全貌。
中间层的神经元数量比输入层少这一点很重要。中间层需要将预测单词所需的信息压缩保存,从而产生密集的向量表示。这时,中间层被写入了我们人类无法解读的代码,这相当于“编码”工作。而从中间层的信息获得期望结果的过程则称为“解码”。这一过程将被编码的信息复原为我们可以理解的形式。
《深度学习进阶:自然语言处理》 Section 3.2 简单的Word2Vec Page 103
模型学习过程
CBOW 模型的学习就是调整权重,以使预测准确。其结果是,权重$ W_{in} $(确切地说是 $ W_{in} $ 和 $ W_{out} $ 两者)学习到蕴含单词出现模式的向量。
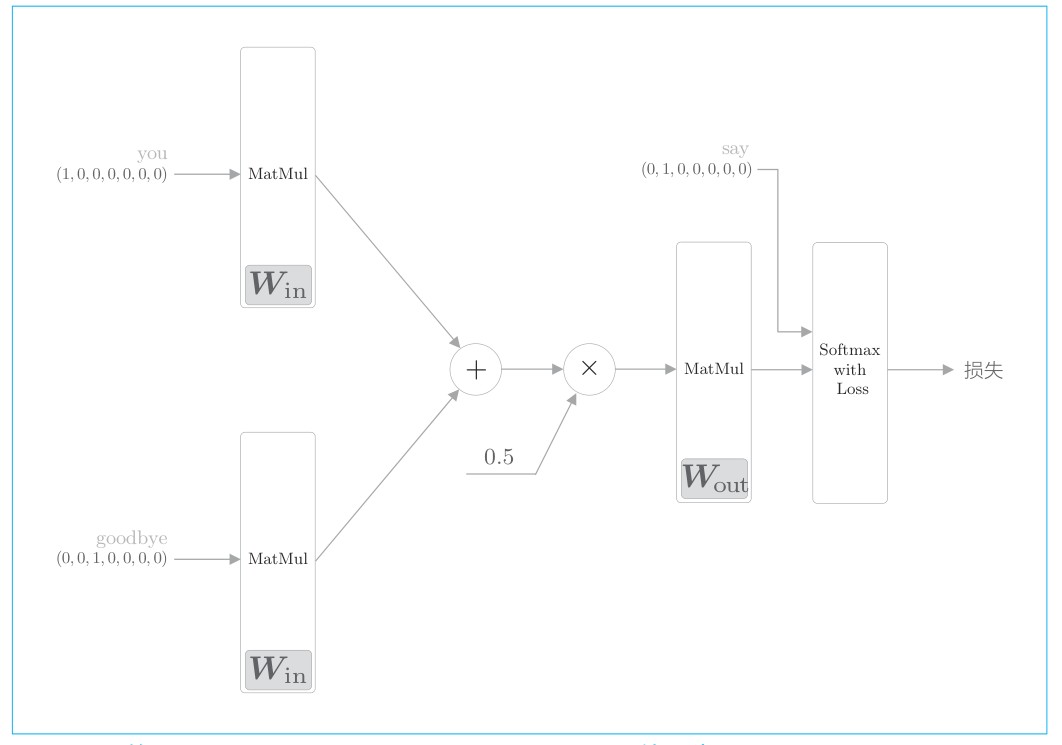
Word2Vec 中使用的网络有两个权重,分别是输入侧的全连接层的权重($ W_{in} $)和输出侧的全连接层的权重($ W_{out} $)。一般而言,输入侧的权重 $ W_{in} $ 的每一行对应于各个单词的分布式表示。另外,输出侧的权重 $ W_{out} $ 也同样保存了对单词含义进行了编码的向量。只是,输出侧的权重在列方向上保存了各个单词的分布式表示。
使用哪个权重作为单词的分布式表示呢?这里有三个选项。
- A. 只使用输入侧的权重
- B. 只使用输出侧的权重
- C. 同时使用两个权重
就 Word2Vec(特别是 skip-gram 模型)而言,最受欢迎的是方案 A。许多研究中也都仅使用输入侧的权重 $ W_{in} $ 作为最终的单词的分布式表示。在与 Word2Vec 相似的 GloVe方法中,通过将两个权重相加,也获得了良好的结果。
Skip-Gram模型
CBOW 模型从上下文的多个单词预测中间的单词(目标词),而 skip-gram 模型则从中间的单词(目标词)预测周围的多个单词(上下文),其网络结构模型如下图所示。
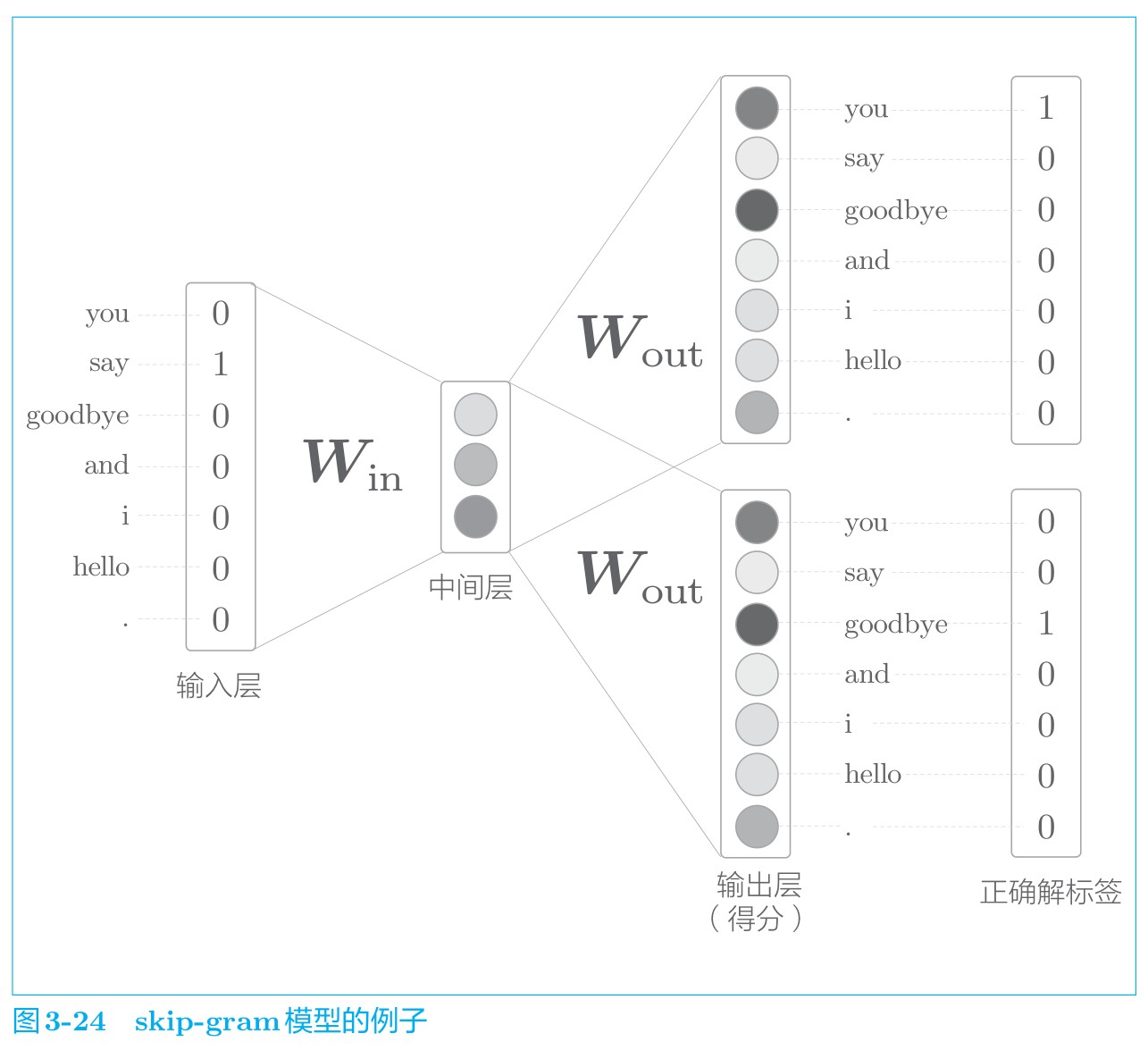
就效果而言,在大多数情况下,skip-gram 模型的结果更好。特别是随着语料库规模的增大,在低频词和类推问题的性能方面,skip-gram 模型往往会有更好的表现; 就学习速度而言,CBOW 模型比 skip-gram 模型要快。这是因为 skip-gram 模型需要根据上下文数量计算相应个数的损失,计算成本变大。
Word2Vec高速化
以CBOW为例,考虑一下Word2Vec的神经网络计算过程,不难发现随着输入量(单词数目)的增大,以下几个计算过程将存在瓶颈:
- A. 输入层(输入层one-hot向量,随着单词数目增加向量增大)和 $W_{in}$ 的矩阵计算
- B. 隐藏层 和 $ W_{out} $ 的矩阵计算
- C. 输出层的Softmax计算
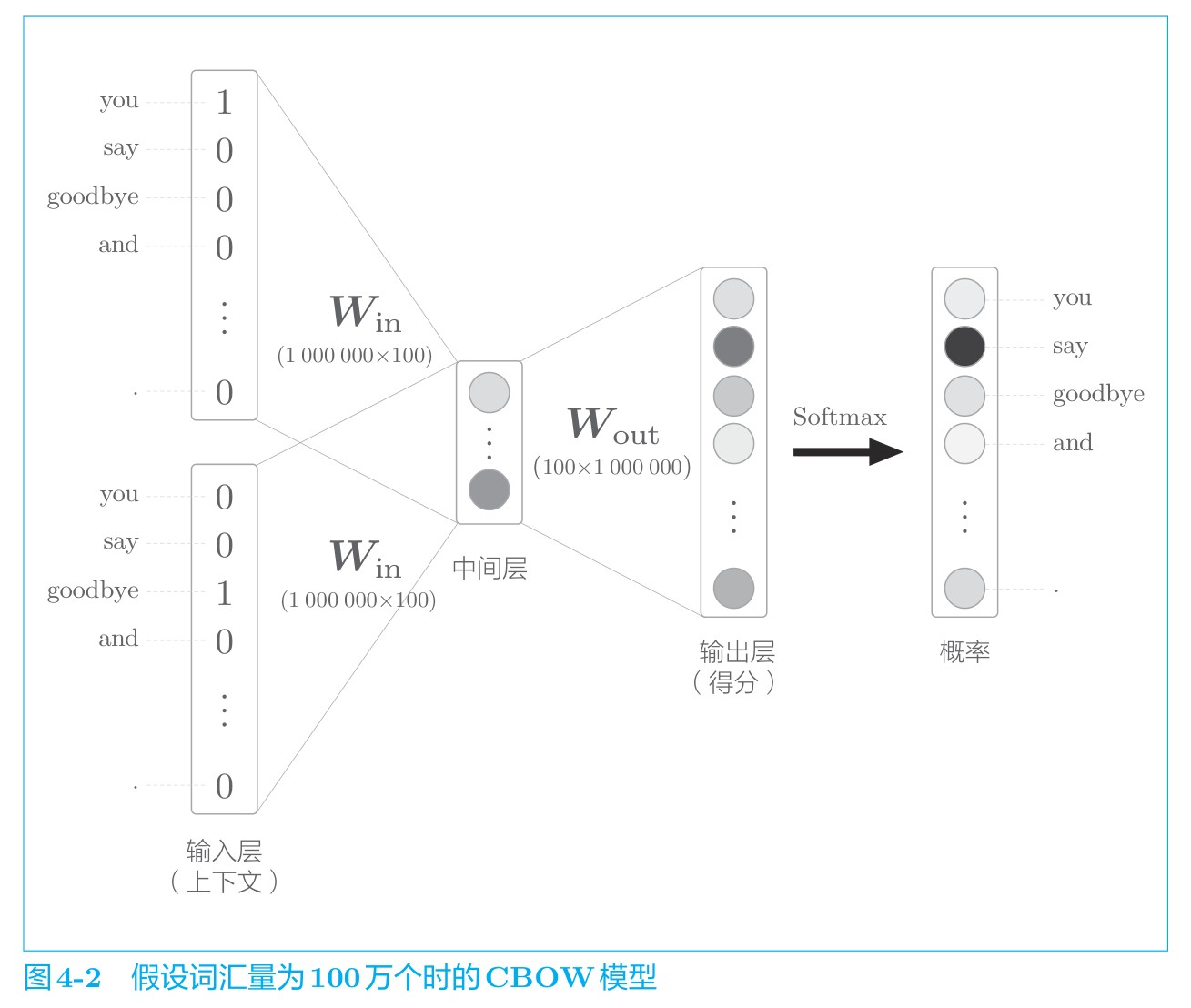
针对A问题,一般引入embedding层优化。针对问题B、C使用层次Softmax和负采样方式解决。
层次Softmax(Hierarchical Softmax)
相对于原始Softmax计算每个单词的向量,层次Softmax(Hierarchical Softmax)使用一颗二叉树来得到每个单词的概率。被验证的效果最好的二叉树类型就是霍夫曼树(Huffman Tree),哈夫曼树保证词频较大的词处于相对浅的层,词频较低的词处于较深的叶子节点,每个词都是哈夫曼树上的一个叶子节点。
| 基于哈夫曼树的Softmax将原本的$ | V | $分类问题(V为单词量),转化为$log | V | $次二分类问题。同样是计算单词$w_t$在上下文的概率,在层次Softmax中变成在哈夫曼树中寻找一条从根节点到目的单词叶子节点的路径,在每一个中间节点都有一次二分类计算(LR分类器)。 |
负采样(Negative Sampling)
负采样利用相对简单的随机负采样,能大幅提升性能,因而可以作为Hierarchical Softmax的一种替代。
基于计数的Glove
基于计数的思路是使用整个语料库的统计数据(共现矩阵和PPMI等),经过一次降维处理(奇异值分解SVD、非负矩阵分解NMF、主成分分析PCA等常用方法)获得单词的分布式表示。
$J = \sum_{i,j=1}^V f(P_{ij})(\mathbf{w}_i^T\mathbf{w}j + b_i + b_j - \log P{ij})^2$
参考文档
- Distributed Representations of Sentences and Documents
- Efficient Estimation of Word Representations in Vector Space
- Word2Vec Parameter Learning Explained
- Glove算法原理及其简单理解
- Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
- 《深度学习进阶:自然语言处理》
- Embeddings in Machine Learning: Everything You Need to Know
- https://www.tensorflow.org/text/guide/word_embeddings
- 用万字长文聊一聊 Embedding 技术