什么是NUMA
非一致性内存访问Non-uniform memory access (NUMA)是多核计算机上的一种内存结构设计模型。这种构架下,不同的内存器件和CPU核心从属不同的Node,每个Node都有自己的集成内存控制器(IMC,Integrated Memory Controller),显而易见的是由于不用共享总线(UMA结构中存在)因此可以提升内存访问效率。
一张图对比NUMA和UMA结构。
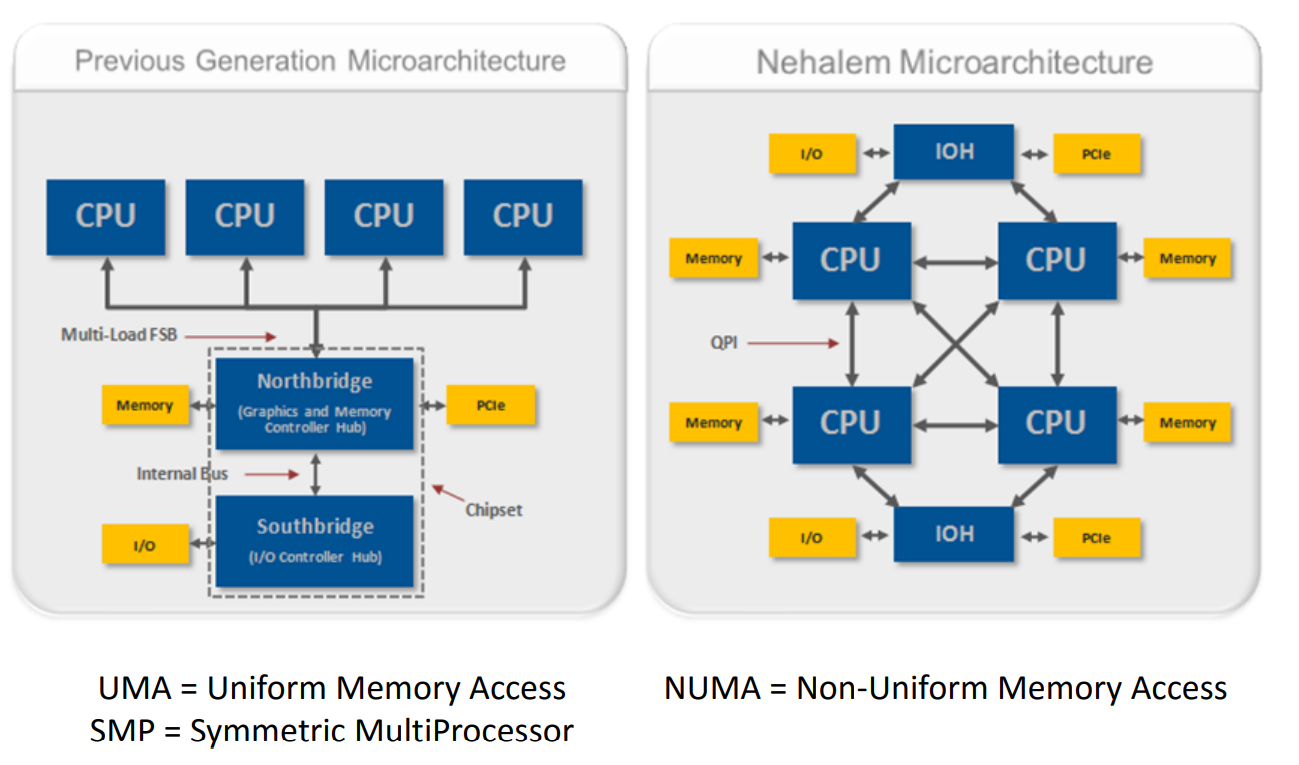
为什么NUMA
在Node内部,架构类似SMP,使用IMC Bus进行不同核心间的通信;不同的Node间通过QPI(Quick Path Interconnect)进行通信,一般来说,一个内存插槽对应一个Node。需要注意的一个特点是,QPI(Quick Path Interconnect)的延迟要高于IMC Bus,也就是说CPU访问内存有了远近(remote/local)之别,而且实验分析来看,这个差别非常明显。因此NUMA可以从硬件架构上提升计算性能,实际使用时可以通过定制虚拟机选项以支持NUMA特性。
怎么玩NUMA
Linux对 NUMA 的支持以及CPU亲和性
CPU亲和性(affinity)就是进程要在某个给定的CPU上尽量长时间地运行而不被迁移到其他处理器的倾向性。
Linux内核进程调度器天生就具有被称为软CPU亲和性(affinity)的特性,这意味着进程通常不会在处理器之间频繁迁移。这种状态正是我们希望的,因为进程迁移的频率小就意味着产生的负载小。
2.6以后的Linux内核还包含了硬CPU亲和性(affinity)编程特性,应用程序可以显式地指定进程在哪个(或哪些)处理器上运行,以下将其称之为绑核操作。
如果有多个线程都需要相同的数据,那么将这些线程绑定到一个特定的CPU上是非常有意义的,这样就确保它们可以访问相同的缓存数据(或者至少可以提高缓存的命中率)。否则,这些线程可能会在不同的CPU上执行,这样会频繁地使其他缓存项失效。
Bot模块在以前压测性能调试过程发现,在bot任务中NUMA机器相对于UMA结构的机器在性能上可以有一倍左右的提升。
小结: 为尽可能的避免跨NUMA访问内存,可以通过设置线程/进程的CPU亲和性来实现NUMA绑核来提高缓存的命中率。
在虚拟机上支持 NUMA
所有现代的 Intel 和 AMD 系统都具有内置于处理器的 NUMA 支持。通常,可以使用 BIOS 设置启用和禁用 NUMA 行为。为确保调度的公平性,一般虚拟机工具默认不会为每个 NUMA 节点(或整体)具有过少内核的系统启用 NUMA 优化,因此需要手动开启NUMA特性。
公司使用的vmware平台上开启NUMA的方法可参见文档 虚拟NUMA控制 。注意numa.vcpu.maxPerVirtualNode参数的设置会影响Mem Node数量
绑定CPU核到Mem Node
cat /proc/sys/kernel/numa_balancing
显示1表明Linux开启了NUMA平衡特性。
numactl -N 0 -m 0
意味着程序将绑在cpu node 0 和mem node 0上。其中4个core为一组cluster,以cluster为单位绑核更加有利于性能发挥,例如core0 - core3为一组cluster,core4-core7为一组cluster。
numactl -C 0-3 -m 0
意味着程序绑定在core0~core3上,内存绑在mem node0上,那么程序最多只能用到4个核,这4个核在一组cluster上。
| 参数名称 | 说明 |
|---|---|
| -N | 绑定CPU节点。 |
| -m | 绑定内存节点。 |
| -C | 绑定CPU核。 |
虚拟机绑核后不会独占绑定的核,已经绑过的核可以再次绑定新的虚拟机,共享使用。例如当前系统启动了16个虚拟机后(每个虚拟机绑4个核),第17个虚拟机可以再次从核0~3开始绑。
查看Mem Node分布
查看内存节点分布, numactl命令还给出了不同节点间的距离,距离越远,跨NUMA内存访问的延时越大。应用程序运行时应减少跨NUMA访问内存。:
如Call使用的压测机器上有2个Mem Node节点,分别绑定了0-7,8-15核。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
root@cvm-172_16_30_88:~ # lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6142M CPU @ 2.60GHz
Stepping: 4
CPU MHz: 2593.906
BogoMIPS: 5187.81
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 22528K
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
...
查看NUMA状态和效果
1
2
3
4
5
6
7
8
root@cvm-172_16_30_231:~ # numastat
node0
numa_hit 26159897164
numa_miss 0
numa_foreign 0
interleave_hit 26095
local_node 26159897164
other_node 0
- numa_hit表示节点内CPU核访问本地内存的次数。
- numa_miss表示节点内核访问其他节点内存的次数。跨节点的内存访问会存在高延迟从而降低性能,因此,numa_miss的值应当越低越好,如果过高,则应当考虑绑核。
NUMA的风险
NUMA结构的缺陷就是2个NODE之间的资源交互慢,因此实际存在内存访问速率分布不均的问题。通常情况下,我们可以通过numa_miss统计查看跨节点访问的严重程度,来指导绑核操作。
参考
- https://support.huaweicloud.com/tuningtip-kunpenggrf/kunpengtuning_12_0009.html
- https://docs.vmware.com/cn/VMware-vSphere/6.5/com.vmware.vsphere.resmgmt.doc/GUID-3E956FB5-8ACB-42C3-B068-664989C3FF44.html