参考列表
- Discovering Modern CPP
- Effective Modern C++
- Effective C++
- C/C++标准/Working Draft, Standard for Programming Language C++
- C/C++工程实践经验谈 by陈硕(giantchen@gmail.com)
内存
new/delete/malloc/free
在c++中,尽量使用new/delete代替malloc/free,两者区别主要体现在构造/析构函数调用行为、对申请失败的处理上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Header <new> synopsis
namespace std {
class bad_alloc;
class bad_array_new_length;
struct nothrow_t {};
extern const nothrow_t nothrow;
typedef void (*new_handler)();
new_handler get_new_handler() noexcept;
new_handler set_new_handler(new_handler new_p) noexcept;
}
void* operator new(std::size_t size);
void* operator new(std::size_t size, const std::nothrow_t&) noexcept;
void operator delete(void* ptr) noexcept;
void operator delete(void* ptr, const std::nothrow_t&) noexcept;
void* operator new[](std::size_t size);
void* operator new[](std::size_t size, const std::nothrow_t&) noexcept;
void operator delete[](void* ptr) noexcept;
void operator delete[](void* ptr, const std::nothrow_t&) noexcept;
void* operator new (std::size_t size, void* ptr) noexcept;
void* operator new[](std::size_t size, void* ptr) noexcept;
void operator delete (void* ptr, void*) noexcept;
void operator delete[](void* ptr, void*) noexcept;
Except for a form called the placement new, the new operator denotes a request for memory allocation on a process’s heap. If sufficient memory is available, new initialises the memory, calling object constructors if necessary, and returns the address to the newly allocated and initialised memory.
If not enough memory is available in the free store for an object of type T, the new request indicates failure by throwing an exception of type std::bad_alloc. This removes the need to explicitly check the result of an allocation.
对于C++来说new分三步步:
- 申请一块内存(operator new), 相当于malloc
- 调用构造函数(placement new)
- 内存分配失败抛出bad_alloc异常。
而delete的操作分两步
- 调用析构函数
- 释放内存,相当于free
智能指针
C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。(简单说就是又一个,RAII的轮子)
理解智能指针需要从下面三个层次:
- 从较浅的层面看,智能指针是利用了RAII(资源获取即初始化)的技术对普通的指针进行封装,这使得智能指针实质是一个对象,行为表现的却像一个指针。
- 智能指针的作用是防止忘记调用delete释放内存和程序异常的进入catch块忘记释放内存。另外指针的释放时机也是非常有考究的,多次释放同一个指针会造成程序崩溃,这些都可以通过智能指针来解决。
- 智能指针还有一个作用是把值语义转换成引用语义。C++和Java有一处最大的区别在于语义不同,在Java里面下列代码:
1 2
Animal a = new Animal(); Animal b = a;
你当然知道,这里其实只生成了一个对象,a和b仅仅是把持对象的引用而已。但在C++中不是这样,
1
2
Animal a;
Animal b = a;
这里却是就是生成了两个对象。
Three new smart-pointer types are introduced in C++11:
unique_ptr,shared_ptr, andweak_ptr. The already existing smart pointer from C ++03 named auto_ptr is generally considered as a failed attempt on the way to unique_ptr since the language was not ready at the time. It should not be used anymore. All smart pointers are defined in the header.
《Effective modern C++》 Item 21: Prefer std::make_unique and std::make_shared to direct use of new.
智能指针的主要实现技术是引用计数,当引用指针的对象数为0时才释放内存,从而避免double free风险。
unique_ptr
no copy allowed, can only be moved.
1
2
3
4
5
unique_ptr < double > dp2 { dp } ; // Error : no copy allowed
dp2 = dp ; // ditto
unique_ptr < double > dp2 { move ( dp )} , dp3 ;
dp3 = move ( dp2 ) ;
shared_ptr
shared_ptr的目标就是,在其所指向的对象不再被使用之后(而非之前),自动释放与对象相关的资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include <iostream>
#include <string>
#include <vector>
#include <memory>
using namespace std;
int main(void)
{
// two shared pointers representing two persons by their name
shared_ptr<string> pNico(new string("nico"));
shared_ptr<string> pJutta(new string("jutta"),
// deleter (a lambda function)
[](string *p)
{
cout << "delete " << *p << endl;
delete p;
}
);
// capitalize person names
(*pNico)[0] = 'N';
pJutta->replace(0, 1, "J");
// put them multiple times in a container
vector<shared_ptr<string>> whoMadeCoffee;
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pNico);
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pNico);
// print all elements
for (auto ptr : whoMadeCoffee)
cout << *ptr << " ";
cout << endl;
// overwrite a name again
*pNico = "Nicolai";
// print all elements
for (auto ptr : whoMadeCoffee)
cout << *ptr << " ";
cout << endl;
// print some internal data
cout << "use_count: " << whoMadeCoffee[0].use_count() << endl;
return 0;
}
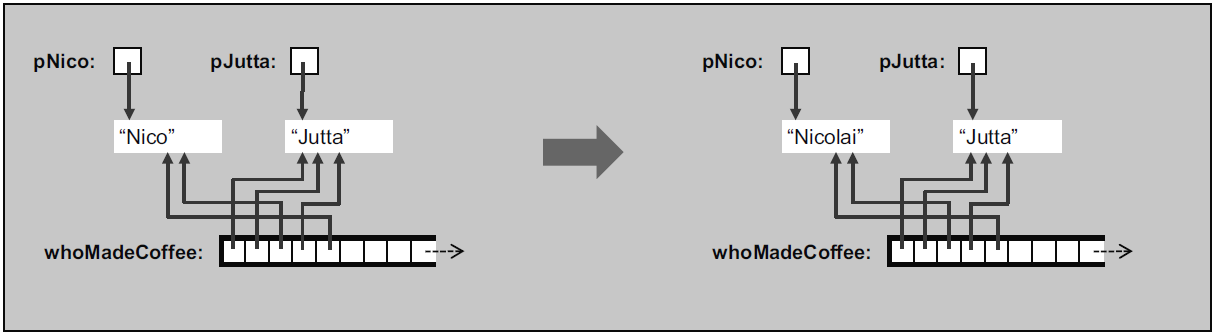
If possible, a shared_ptr should be created with make_shared:
1
shared_ptr < double > p1 = make_shared < double >() ;
Then the management and business data are stored together in memory —and the memory caching is more efficient.
waek_ptr
避免weak_ptr的出现,人为排除shared pointer的循环引用。个人理解弱指针不一定可用,当内存被销毁时,会指向空指针,使用前需要检查可用性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <iostream>
#include <memory>
int main() {
{
std::shared_ptr<int> sh_ptr = std::make_shared<int>(10);
std::cout << sh_ptr.use_count() << std::endl;
std::weak_ptr<int> wp(sh_ptr);
std::cout << wp.use_count() << std::endl;
if(!wp.expired()){
std::shared_ptr<int> sh_ptr2 = wp.lock(); //get another shared_ptr
*sh_ptr = 100;
std::cout << wp.use_count() << std::endl;
}
}
//delete memory
}
函数
构造函数和析构函数
着重关注一下构造和析构函数。
C ++ has six methods (four in C ++03) with a default behavior:
- Default constructor
- Copy constructor
- Move constructor (C ++11 or higher)
- Copy assignment
- Move assignment (C++11 or higher)
- Destructor
explicit构造函数: 防止构造函数的隐式转换带来的错误或者误解。
move构造函数:语法特性来提高效率减少拷贝动作。(除非不得已,还是在算法上提升效率吧,move语义的效果也很鸡肋,除非有大块内存的拷贝可以考虑使用,另外,参考swap语义)。
1
2
3
4
5
6
7
8
9
class vector
{
vector & operator =( vector && src )
{
assert ( my_size == 0 || my_size == src.my_size);
std :: swap ( data , src . data );
return * this ;
}
};
构造和析构函数使得c++类有一个重要特点:Resource Acquisition Is Initialization (RAII) ,对象在生命周期内完成资源的自我管理(恩,对自己负责原则,Single Responsibility Principle)。多个对象引用同一块内存的情况可配合shared_ptr效果更佳。
仿函数
仿函数(functor):就是类中实现一个operator(),这个类就有了类似函数的行为。
使用场景:把通用的功能块写成全局函数或者定位为类成员都不合适的情况下使用。
lambda
匿名函数语法糖,编译器会给你写一个仿函数出来,权当为了使std::algorithm更可用的一点补充。
C++本身的问题是:没有lambda的话,函数对象的定义太麻烦了!你得定义一个类,重载operator(),然后再创建这个类的实例…所以lambda表达式可以看成是函数对象的语法糖,在你需要的时候,它可以很简洁地给你生成一个函数对象。
函数式编程惯用语
- Filter :remove unwanted items
- map :apply a transformation
- Reduce :reduce sequences to a single value
虚函数
一般重载函数调用都是在编译时根据参数和函数名确定的,而虚函数虚在所谓“推迟联编”或者“动态联编”上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数,所以被成为“虚”函数。动态确定哪个函数实现被调用就需要虚函数表来“指示”。
小结起来就是:
- 动态:在运行时决定调用(相对的静态在编译时决定,如函数重载、模板类的非虚函数调用)
- 单分派:基于类型选择调用(相对于多分派,即由多个类型决定调用,涉及double dispatch模式)
- 子类多态:子类可多种实现
先写一个demo看虚函数的行为。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
#include <iostream>
#include <iomanip>
#define PRINT_FUCCTION_MESSAGE() std::cout << std::setw(10) << typeid(this).name() \
<< std::setw(10) << "@" << __FUNCTION__ \
<< std::endl
class Base{
public:
Base(){PRINT_FUCCTION_MESSAGE();}
void func(){PRINT_FUCCTION_MESSAGE();}
virtual void vfunc(){PRINT_FUCCTION_MESSAGE();}
virtual ~Base(){PRINT_FUCCTION_MESSAGE();}
};
class A: public Base{
public:
A(){PRINT_FUCCTION_MESSAGE();}
void func(){PRINT_FUCCTION_MESSAGE();}
virtual void vfunc(){PRINT_FUCCTION_MESSAGE();}
~A(){PRINT_FUCCTION_MESSAGE();}
};
class B: public Base{
public:
B(){PRINT_FUCCTION_MESSAGE();}
void func(){PRINT_FUCCTION_MESSAGE();}
virtual void vfunc(){PRINT_FUCCTION_MESSAGE();}
~B(){PRINT_FUCCTION_MESSAGE();}
};
int main (int, char**){
std::cout << "----------------------------" << std::endl;
Base* base = new Base;
A* a = new A;
B* b = new B;
std::cout << "----------------------------" << std::endl;
base->func();
a->func();
b->func();
std::cout << "----------------------------" << std::endl;
base->vfunc();
a->vfunc();
b->vfunc();
std::cout << "----------------------------" << std::endl;
Base* bb = static_cast<Base*>(a);
bb->vfunc();
bb->func();
std::cout << "----------------------------" << std::endl;
delete base;
delete a;
delete b;
return 0;
}
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
----------------------------
P4Base @Base
P4Base @Base
P1A @A
P4Base @Base
P1B @B
----------------------------
P4Base @func
P1A @func
P1B @func
----------------------------
P4Base @vfunc
P1A @vfunc
P1B @vfunc
----------------------------
P1A @vfunc
P4Base @func
----------------------------
P4Base @~Base
P1A @~A
P4Base @~Base
P1B @~B
P4Base @~Base
按 <RETURN> 来关闭窗口...
在写接口时虚函数比较有用,可以规定子类需要重载的函数,实现多态。 另外,此处的继承需要注意构造函数和析构函数的调用顺序,防止出现资源double free的情况。
为什么 C++ 中使用虚函数时会影响效率?
调用虚函数的时候,首先根据对象里存储的虚函数表指针vptr,找到虚函数表vtables,再根据偏移量找到哪一项,再找到虚函数地址
不知道什么时开始虚函数的实现被面试官频繁地问到,真的有用么。
«Master Mordern C++» 6.1.3 Virtual Functions and Polymorphic Classes
To realize these dynamic function calls, the compiler maintains Virtual Function Tables (a.k.a. Virtual Method Tables) or Vtables. They contain function pointers through which each virtual method of the actual object is called. The reference pr has the type person& and refers to an object of type student. Through the vtable of pr, the call of all_info() is directed to student::all_info. This indirection over function pointers adds some extra cost to virtual functions which is significant for tiny functions and negligible for sufficiently large functions.
按照the C++PL的说法,虚函数调用比普通成员函数慢至多25%
bind/function
Scott Meyers 的 Effective C++ 3rd 第 35 条款提到了以 boost::function和 boost:bind 取代虚函数的做法 boost::function可以指向任何函数,包括成员函数。当用bind把某个成员函数绑到某个对象上时,我们得到了一个 closure(闭包)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include <iostream>
#include <iomanip>
#include <functional>
#define PRINT_FUCCTION_MESSAGE() std::cout << std::setw(10) << typeid(this).name() \
<< std::setw(10) << "@" << __FUNCTION__ \
<< std::endl
class button
{
public:
std::function<void()> onClick;
};
class player
{
public:
void play(){ PRINT_FUCCTION_MESSAGE();}
void stop(){ PRINT_FUCCTION_MESSAGE();}
};
button playButton, stopButton;
player thePlayer;
void connect()
{
playButton.onClick = std::bind(&player::play, &thePlayer);
stopButton.onClick = std::bind(&player::stop, &thePlayer);
}
int main(int argc, char *argv[])
{
connect();
playButton.onClick();
stopButton.onClick();
return 0;
}
输出:
1
2
P6player @play
P6player @stop
面向对象程序设计模型
面向对象三板斧:封装、继承和多态。抛开面向对象不谈,工程设计上封装绝对在最重要的位置,良好的封装是清晰的代码层次的必要条件。继承和多态相对来说属于锦上添花的特性,能用好最好,用的不好会带来不必要的耦合,增加抽象的复杂性。
STL中的一些常用算法
最常用的部分包括:
- for_each
- find
- find_if
- remove_if
- replace_if
- sort
- fill_n
配合函数对象或者lamba使用很多常规方法可以写得不那么啰嗦,提高可读性。贴上一段最近项目中的相关代码片段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
class ProjectIndexerInfo{
public:
QString name;
QString confFile;
ProjectIndexerInfo(){}
ProjectIndexerInfo(TestProject& project)
: name(project.name),
confFile(project.confFile){}
// 如果包含关键字,返回true
bool operator[](QString keyword){
return name.contains(keyword, Qt::CaseInsensitive);
}
};
/**
* @brief The ProjectIndexer class 搜索实现类,尽可能在结果中搜索
*/
class ProjectIndexer{
public:
std::vector<ProjectIndexerInfo> infos;
std::vector<uint> result;
QString key;
~ProjectIndexer(){
infos.clear();
}
void remove(uint id){
if((size_t)id < infos.size()){
infos.erase(infos.begin()+id);
std::remove_if(result.begin(), result.end(), [&id](const uint& value){
return id == value;
});
}
}
int search(QString keyword){
if(keyword.isEmpty()){
key = keyword;
result.clear();
for(size_t i = 0; i < infos.size(); i++){
result.push_back(i);
}
return result.size();
}
bool searchInResult = false;
if((!key.isEmpty()) && (!keyword.isEmpty()) &&
keyword.contains(key,Qt::CaseInsensitive)){
searchInResult = true;
}
key = keyword;
if(searchInResult){
// 结果中搜索
result.erase(std::remove_if(result.begin(), result.end(), [this,&keyword](const uint& id){
if((size_t)id < infos.size()){
ProjectIndexerInfo item = this->infos.at(id);
if(!item[keyword]){
return true;
}else{
return false;
}
}else{
g_error() << "not found" << id;
return true;
}
}), result.end());
}else{
// 全局搜索
result.clear();
int idx = 0;
std::for_each(infos.begin(), infos.end(), [this,&idx,&keyword](ProjectIndexerInfo& item){
if(item[keyword]){
result.push_back(idx);
}
idx++;
});
}
return result.size();
}
};
查找算法
| 名称 | 算法解释 |
|---|---|
| 查找算法 | 判断容器中是否包含某个值 |
| adjacent_find | 在iterator对标识元素范围内,查找一对相邻重复元素,找到则返回指向这对元素的第一个元素的ForwardIterator。否则返回last。重载版本使用输入的二元操作符代替相等的判断。 |
| binary_search | 在有序序列中查找value,找到返回true。重载的版本实用指定的比较函数对象或函数指针来判断相等。 |
| count | 利用等于操作符,把标志范围内的元素与输入值比较,返回相等元素个数。 |
| count_if | 利用输入的操作符,对标志范围内的元素进行操作,返回结果为true的个数。 |
| equal_range | 功能类似equal,返回一对iterator,第一个表示lower_bound,第二个表示upper_bound。 |
| find | 利用底层元素的等于操作符,对指定范围内的元素与输入值进行比较。当匹配时,结束搜索,返回该元素的一个InputIterator。 |
| find_end | 在指定范围内查找”由输入的另外一对iterator标志的第二个序列”的最后一次出现。找到则返回最后一对的第一个ForwardIterator,否则返回输入的”另外一对”的第一个ForwardIterator。重载版本使用用户输入的操作符代替等于操作。 |
| find_first_of | 在指定范围内查找”由输入的另外一对iterator标志的第二个序列”中任意一个元素的第一次出现。重载版本中使用了用户自定义操作符。 |
| find_if | 使用输入的函数代替等于操作符执行find。 |
| lower_bound | 返回一个ForwardIterator,指向在有序序列范围内的可以插入指定值而不破坏容器顺序的第一个位置。重载函数使用自定义比较操作。 |
| upper_bound | 返回一个ForwardIterator,指向在有序序列范围内插入value而不破坏容器顺序的最后一个位置,该位置标志一个大于value的值。重载函数使用自定义比较操作。 |
| search | 给出两个范围,返回一个ForwardIterator,查找成功指向第一个范围内第一次出现子序列(第二个范围)的位置,查找失败指向last1。重载版本使用自定义的比较操作。 |
| search_n | 在指定范围内查找val出现n次的子序列。重载版本使用自定义的比较操作。 |
排序和通用算法
| 名称 | 算法解释 |
|---|---|
| 排序和通用算法(14个) | 提供元素排序策略 |
| inplace_merge | 合并两个有序序列,结果序列覆盖两端范围。重载版本使用输入的操作进行排序。 |
| merge | 合并两个有序序列,存放到另一个序列。重载版本使用自定义的比较。 |
| nth_element | 将范围内的序列重新排序,使所有小于第n个元素的元素都出现在它前面,而大于它的都出现在后面。重载版本使用自定义的比较操作。 |
| partial_sort | 对序列做部分排序,被排序元素个数正好可以被放到范围内。重载版本使用自定义的比较操作。 |
| partial_sort_copy | 与partial_sort类似,不过将经过排序的序列复制到另一个容器。 |
| partition | 对指定范围内元素重新排序,使用输入的函数,把结果为true的元素放在结果为false的元素之前。 |
| random_shuffle | 对指定范围内的元素随机调整次序。重载版本输入一个随机数产生操作。 |
| reverse | 将指定范围内元素重新反序排序。 |
| reverse_copy | 与reverse类似,不过将结果写入另一个容器。 |
| rotate | 将指定范围内元素移到容器末尾,由middle指向的元素成为容器第一个元素。 |
| rotate_copy | 与rotate类似,不过将结果写入另一个容器。 |
| sort | 以升序重新排列指定范围内的元素。重载版本使用自定义的比较操作。 |
| stable_sort | 与sort类似,不过保留相等元素之间的顺序关系。 |
| stable_partition | 与partition类似,不过不保证保留容器中的相对顺序。 |
删除和替换算法
| 名称 | 算法解释 |
|---|---|
| copy | 复制序列 |
| copy_backward | 与copy相同,不过元素是以相反顺序被拷贝。 |
| iter_swap | 交换两个ForwardIterator的值。 |
| remove | 删除指定范围内所有等于指定元素的元素。注意,该函数不是真正删除函数。内置函数不适合使用remove和remove_if函数。 |
| remove_copy | 将所有不匹配元素复制到一个制定容器,返回OutputIterator指向被拷贝的末元素的下一个位置。 |
| remove_if | 删除指定范围内输入操作结果为true的所有元素。 |
| remove_copy_if | 将所有不匹配元素拷贝到一个指定容器。 |
| replace | 将指定范围内所有等于vold的元素都用vnew代替。 |
| replace_copy | 与replace类似,不过将结果写入另一个容器。 |
| replace_if | 将指定范围内所有操作结果为true的元素用新值代替。 |
| replace_copy_if | 与replace_if,不过将结果写入另一个容器。 |
| swap | 交换存储在两个对象中的值。 |
| swap_range | 将指定范围内的元素与另一个序列元素值进行交换。 |
| unique | 清除序列中重复元素,和remove类似,它也不能真正删除元素。重载版本使用自定义比较操作。 |
| unique_copy | 与unique类似,不过把结果输出到另一个容器。 |
排列组合算法
| 名称 | 算法解释 |
|---|---|
| next_permutation | 取出当前范围内的排列,并重新排序为下一个排列。重载版本使用自定义的比较操作。 |
| prev_permutation | 取出指定范围内的序列并将它重新排序为上一个序列。如果不存在上一个序列则返回false。重载版本使用自定义的比较操作。 |
算术算法
| 名称 | 算法解释 |
|---|---|
| accumulate | iterator对标识的序列段元素之和,加到一个由val指定的初始值上。重载版本不再做加法,而是传进来的二元操作符被应用到元素上。 |
| partial_sum | 创建一个新序列,其中每个元素值代表指定范围内该位置前所有元素之和。重载版本使用自定义操作代替加法。 |
| inner_product | 对两个序列做内积(对应元素相乘,再求和)并将内积加到一个输入的初始值上。重载版本使用用户定义的操作。 |
| adjacent_difference | 创建一个新序列,新序列中每个新值代表当前元素与上一个元素的差。重载版本用指定二元操作计算相邻元素的差。 |
生成和异变算法
| 名称 | 算法解释 |
|---|---|
| fill | 将输入值赋给标志范围内的所有元素。 |
| fill_n | 将输入值赋给first到first+n范围内的所有元素。 |
| for_each | 用指定函数依次对指定范围内所有元素进行迭代访问,返回所指定的函数类型。该函数不得修改序列中的元素。 |
| generate | 连续调用输入的函数来填充指定的范围。 |
| generate_n | 与generate函数类似,填充从指定iterator开始的n个元素。 |
| transform | 将输入的操作作用与指定范围内的每个元素,并产生一个新的序列。重载版本将操作作用在一对元素上,另外一个元素来自输入的另外一个序列。结果输出到指定容器。 |
关系算法
| 名称 | 算法解释 |
|---|---|
| equal | 如果两个序列在标志范围内元素都相等,返回true。重载版本使用输入的操作符代替默认的等于操作符。 |
| includes | 判断第一个指定范围内的所有元素是否都被第二个范围包含,使用底层元素的<操作符,成功返回true。重载版本使用用户输入的函数。 |
| lexicographical_compare | 比较两个序列。重载版本使用用户自定义比较操作。 |
| max | 返回两个元素中较大一个。重载版本使用自定义比较操作。 |
| max_element | 返回一个ForwardIterator,指出序列中最大的元素。重载版本使用自定义比较操作。 |
| min | 返回两个元素中较小一个。重载版本使用自定义比较操作。 |
| min_element | 返回一个ForwardIterator,指出序列中最小的元素。重载版本使用自定义比较操作。 |
| mismatch | 并行比较两个序列,指出第一个不匹配的位置,返回一对iterator,标志第一个不匹配元素位置。如果都匹配,返回每个容器的last。重载版本使用自定义的比较操作。 |
集合算法
| 名称 | 算法解释 |
|---|---|
| set_union | 构造一个有序序列,包含两个序列中所有的不重复元素。重载版本使用自定义的比较操作。 |
| set_intersection | 构造一个有序序列,其中元素在两个序列中都存在。重载版本使用自定义的比较操作。 |
| set_difference | 构造一个有序序列,该序列仅保留第一个序列中存在的而第二个中不存在的元素。重载版本使用自定义的比较操作。 |
| set_symmetric_difference | 构造一个有序序列,该序列取两个序列的对称差集(并集-交集)。 |
堆算法
| 名称 | 算法解释 |
|---|---|
| make_heap | 把指定范围内的元素生成一个堆。重载版本使用自定义比较操作。 |
| pop_heap | 并不真正把最大元素从堆中弹出,而是重新排序堆。它把first和last-1交换,然后重新生成一个堆。可使用容器的back来访问被”弹出”的元素或者使用pop_back进行真正的删除。重载版本使用自定义的比较操作。 |
| push_heap | 假设first到last-1是一个有效堆,要被加入到堆的元素存放在位置last-1,重新生成堆。在指向该函数前,必须先把元素插入容器后。重载版本使用指定的比较操作。 |
| sort_heap | 对指定范围内的序列重新排序,它假设该序列是个有序堆。重载版本使用自定义比较操作。 |
一些工程性问题
二进制兼容性
兼容性问题是怎么来的
这个问题在《C++工程实践经验谈 by陈硕(giantchen@gmail.com)》中被着重提起。
有哪些情况会破坏库的 ABI到底如何判断一个改动是不是二进制兼容呢?这跟 C++ 的实现方式直接相关,虽然 C++ 标准没有规定 C++ 的 ABI,但是几乎所有主流平台都有明文或事实上的 ABI 标准。比方说 ARM 有 EABI,Intel Itanium 有 Itanium ABI 10 ,x86-64 有仿Itanium 的 ABI,SPARC 和 MIPS 也都有明文规定的 ABI,等等。x86 是个例外,它只有事实上的 ABI,比如 Windows 就是 Visual C++,Linux 是 G++(G++ 的 ABI还有多个版本,目前最新的是 G++ 3.4 的版本) ,Intel 的 C++ 编译器也得按照 VisualC++ 或 G++ 的 ABI 来生成代码,否则就不能与系统其它部件兼容。
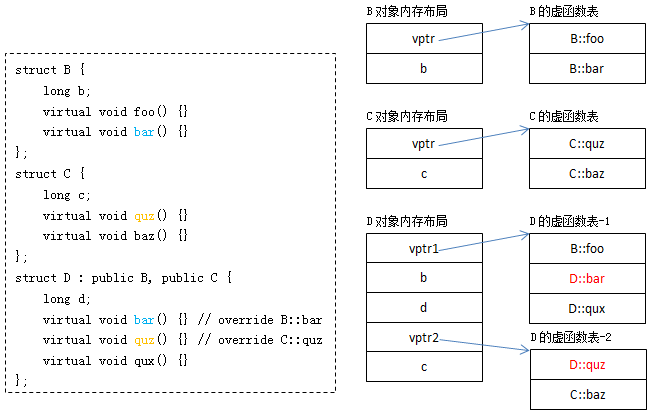
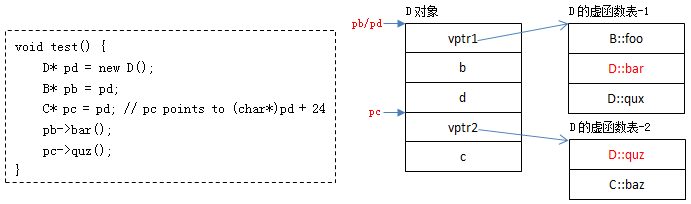
C++ ABI 的主要内容:
- 函数参数传递的方式,比如 x86-64 用寄存器来传函数的前 4 个整数参数
- 虚函数的调用方式,通常是 vptr/vtbl 然后用 vtbl[offset] 来调用
- struct 和 class 的内存布局,通过偏移量来访问数据成员
- name mangling
- RTTI 和异常处理的实现(以下本文不考虑异常处理)
C/C++ 通过头文件暴露出动态库的使用方法,这个“使用方法”主要是给编译器看的,编译器会据此生成二进制代码,然后在运行的时候通过装载器 (loader) 把可执行文件和动态库绑到一起。如何判断一个改动是不是二进制兼容,主要就是看头文件暴露的这份“使用说明”能否与新版本的动态库的实际使用方法兼容。因为新的库必然有新的头文件,但是现有的二进制可执行文件还是按旧的头文件来调用动态库。
这里举一些源代码兼容但是二进制代码不兼容例子
- 给函数增加默认参数,现有的可执行文件无法传这个额外的参数。
- 增加虚函数,会造成 vtbl 里的排列变化。(不要考虑“只在末尾增加”这种取巧行为,因为你的 class 可能已被继承。)
- 增加默认模板类型参数,比方说 Foo
改为 Foo<T, Alloc=alloc >,这会改变 name mangling - 改变 enum 的值,把 enum Color { Red = 3 }; 改为 Red = 4。这会造成错位。当然,由于 enum 自动排列取值,添加 enum 项也是不安全的,在末尾添加除外。
给 class Bar 增加数据成员,造成 sizeof(Bar) 变大,以及内部数据成员的offset 变化,这是不是安全的?通常不是安全的,但也有例外。
- 如果客户代码里有 new Bar,那么肯定不安全,因为 new 的字节数不够装下新Bar 对象。相反,如果 library 通过 factory 返回 Bar* (并通过 factory 来销毁对象)或者直接返回 shared_ptr
,客户端不需要用到 sizeof(Bar),那么可能是安全的。 - 如果客户代码里有 Bar* pBar; pBar->memberA = xx;,那么肯定不安全,因为memberA 的新 Bar 的偏移可能会变。相反,如果只通过成员函数来访问对象的数据成员,客户端不需要用到 data member 的 offsets,那么可能是安全的。
- 如果客户调用 pBar->setMemberA(xx); 而 Bar::setMemberA() 是个 inline func-tion,那么肯定不安全,因为偏移量已经被 inline 到客户的二进制代码里了。如果 setMemberA() 是 outline function,其实现位于 shared library 中,会随着Bar 的更新而更新,那么可能是安全的。
那么只使用 header-only 的库文件是不是安全呢?不一定。如果你的程序用了boost 1.36.0,而你依赖的某个 library 在编译的时候用的是 1.33.1,那么你的程序和这个 library 就不能正常工作。因为 1.36.0 和 1.33.1 的 boost::function 的模板参数类型的个数不一样,后者一个多了 allocator。
哪些做法多半是安全的
前面我说“不能轻易修改”,暗示有些改动多半是安全的,这里有一份白名单,欢迎添加更多内容。只要库改动不影响现有的可执行文件的二进制代码的正确性,那么就是安全的,我们可以先部署新的库,让现有的二进制程序受益。
- 增加新的 class
- 增加 non-virtual 成员函数或 static 成员函数
- 修改数据成员的名称,因为生产的二进制代码是按偏移量来访问的,当然,这会造成源码级的不兼容。
- 还有很多,不一一列举了。
欢迎补充